
在 上次的文章 中,我大致介绍了如何使用Calibre来管理本子。
使用Calibre管理本子,好处不少,但就是录入的过程太麻烦。如果本子少那还好说,如果本子多的话,一个个录入要录入到什么时候?
对于这个问题,也有相应的解决方案。现在让我来介绍,我是如何批量录入本子的。
今天的文章需要一点程序方面的知识,对于部分读者可能有一些难度。
前言
批量录入本子的基本步骤与手工录入相似,大致可分为 准备文件、录入基本元数据、录入高级元数据、后续处理 四个基本步骤。
准备文件,如果文件简单使用 Embed Comic Metadata 插件即可搞定,如果文件比较复杂则需要使用相应的脚本。
录入基本元数据,可使用正则式进行匹配。
录入高级元数据,可添加元数据来源插件,然后批量从网络下载。
后续处理,即对下载的元数据进行相应的检查,转换。该步骤部分操作可在录入高级元数据的过程中进行。
为了便于读者理解,本文将使用一个合集文件进行讲解,具体讲述如何进行这四个步䯅。
准备文件
所谓准备文件,即是准备好可以直接添加进Calibre书库的文件。
由于Calibre原生只支持zip格式的文件,可相当一部分压缩包符合要求(压缩包内仅含图片文件),但却是rar格式,对于这种文件,我称这为简单文件,对于这类文件,安装 Embed Comic Metadata 插件后,即可直接添加进Calibre书库。
如果压缩包含有密码,或里面夹杂有其它文件,我称其为复杂文件,对于此类文件可以使用脚本进行处理。
简单文件
由于简单文件,使用插件后即可搞定,所以此节主要讲解如何安装插件。
插件的两种安装方法
方法一
打开 Preferences-Plugins 介面,点击 Get new plugins,在右上角搜索框中 输入 Embed Comic Metadata,选中相应条目,点击 Install。
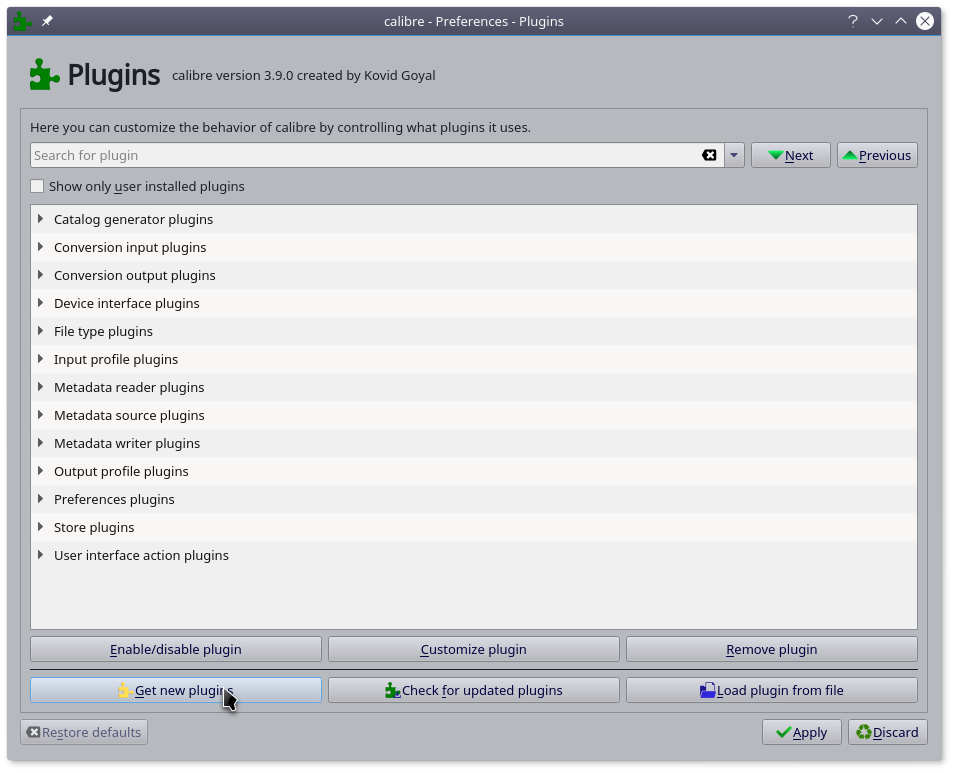
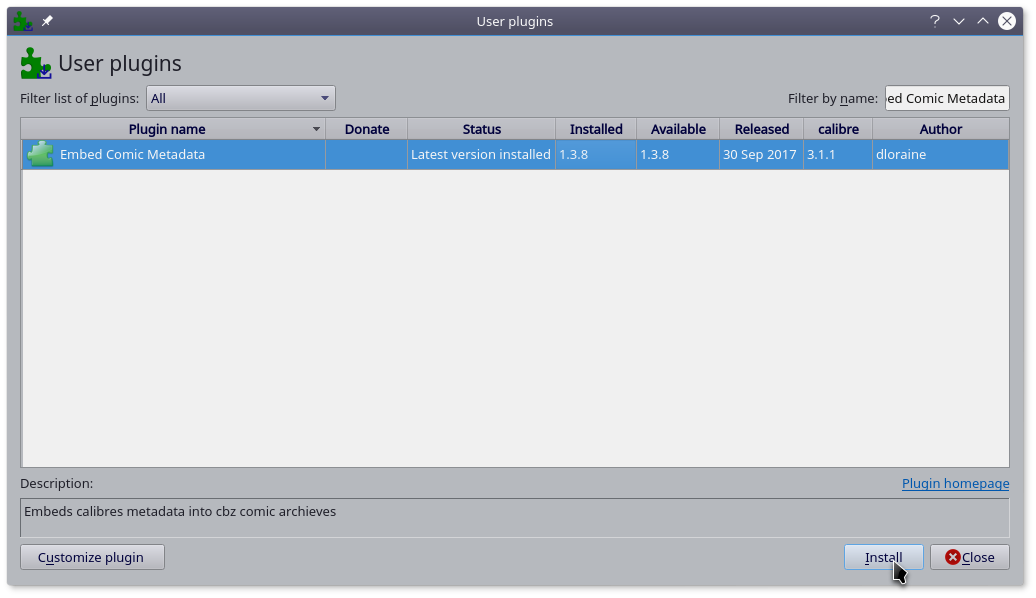
方法二
打开 Embed Comic Metadata 插件主页 ,下载 相应的压缩包。
打开 Preferences-Plugins 介面,点击 Load plugin from file,选择相应文件进行安装。
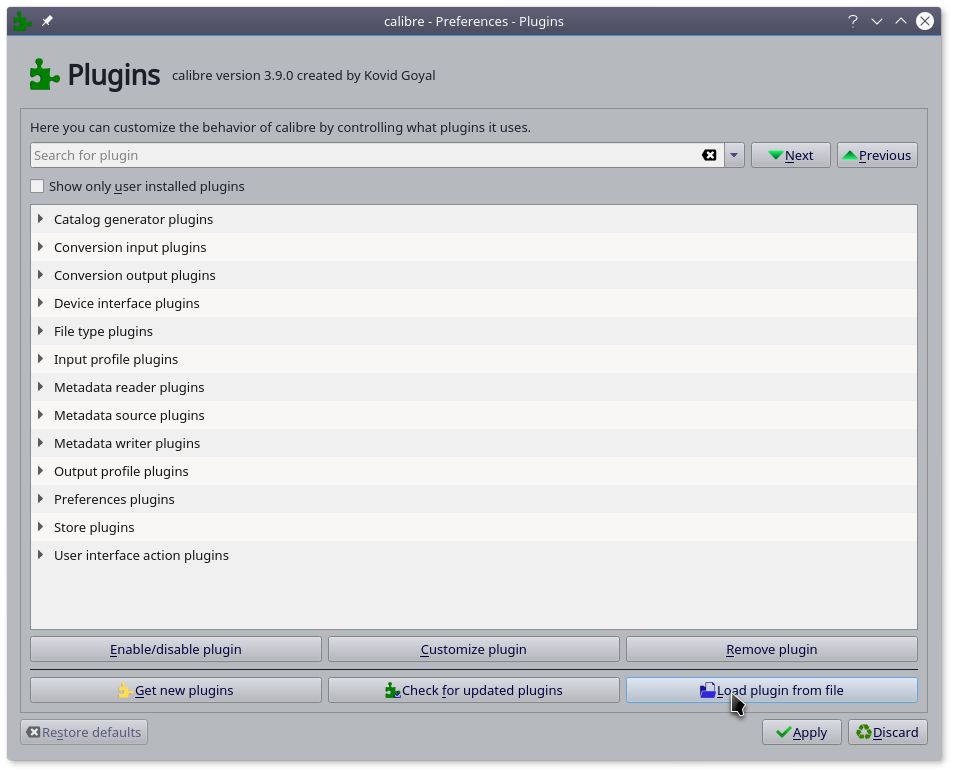
安装完成后,当导入rar文件(7z不可以)时,calibre会自动识别,将其转换为cbr文件。特别提醒:
在阅读 录入基本元数据 之前,请不要向Calibre书库中导入书籍。
Calibre 导入书籍的过程,会自动读取相应的元数据,请配置好正则表达式后再向 Calibre 书库中添加书籍。该文件可使用漫画阅读器阅读。请在文件管理器中,修改cbr文件默认打开方式。
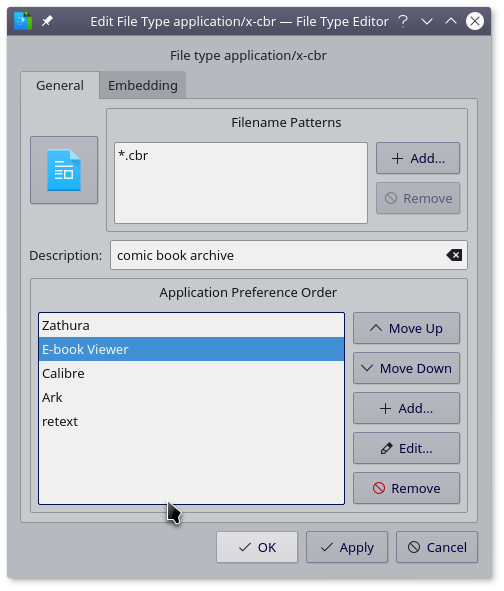
另外,为了兼容性,建议将cbr格式转换为cbz格式。
选中要转换的书籍,点击主界面 Embed Comic Metadata图标 右侧三角 (不是图标本身),点击 Only covert to cbz。[1]
为了节省硬盘空间,可右侧三角中点击 Configure,进入插件设置页面 [2] ,勾选 Delete cbr after conversion。
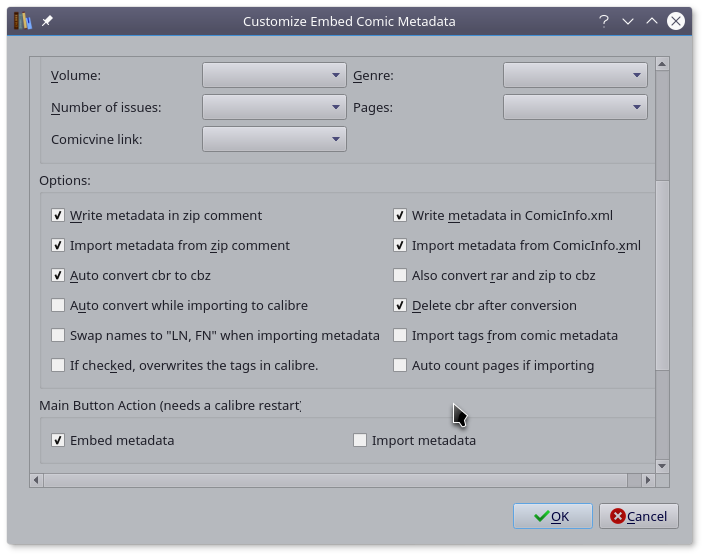
| [1] | 转换速度和本子大小相关。开始转换后请耐心等待,中途电脑很可能会卡住,这时出去喝杯水,休息一会。 |
| [2] | 也可在 Preferences-Plugins 介面,双击 Embed Comic Metadata 条目,进入设置选项。 |
复杂文件
使用上面的插件已经足够应对90%的情況了。
但对于一些特殊的情況(比如说压缩包有密码),还是没有办法,对于这些场景,可以使用本人编写的转换脚本。
你可以下载 转换脚本的模板 ,使用时根据具体情況,进行相应的修改(去除相应行的行 注释 ,如有密码修改还需修改相应变量的值),然后将修改后的脚本放入压缩包文件存放目录,运行即可。
脚本运行后, origin 目录下存放原压缩文件, converted 目录下存放转换后的压缩文件。
注意:
由于本人的系统是Linux,所以本节提供的脚本为bash脚本。
bash脚本并不能在直接在Windows下运行,你可以在Windows系统下安装 Cygwin ,如果你的电脑系统为 Windows 10 还可以使用 Windows Subsystem For Linux 。
你可以参考这个网页。
录入基本元数据
图书的元数据很多,但最基本的便是题名与作者两项。
由于本子的文件名一般都包括作者、题名,而且有一定的格式,因此在Calibre中进行相关设置,让Calibre在导入书籍时从文件名中自动识出基本出元数据。
经过多次尝试找到了可以从大多数本子文件名中匹配出题名与作者的正则表达式,表达式如下:
(.*?\[((?:(?!汉化|漢化)[^\[\]])*)\](?:\s*(?:\[[^\(\)]+\]|\([^\[\]\(\)]+\))\s*)*([^\[\]\(\)]+).*) (?P<comments>.*?\[(?P<author>(?:(?!汉化|漢化)[^\[\]])*)\](?:\s*(?:\[[^\(\)]+\]|\([^\[\]\(\)]+\))\s*)*(?P<title>[^\[\]\(\)]+).*)
使用方法,打开Calbire的 Preferences-Adding books 界面,在 Regular expression 栏中填入下方的正则表达式。
(?P<comments>.*?\[(?P<author>(?:(?!汉化|漢化)[^\[\]])*)\](?:\s*(?:\[[^\(\)]+\]|\([^\[\]\(\)]+\))\s*)*(?P<title>[^\[\]\(\)]+).*)
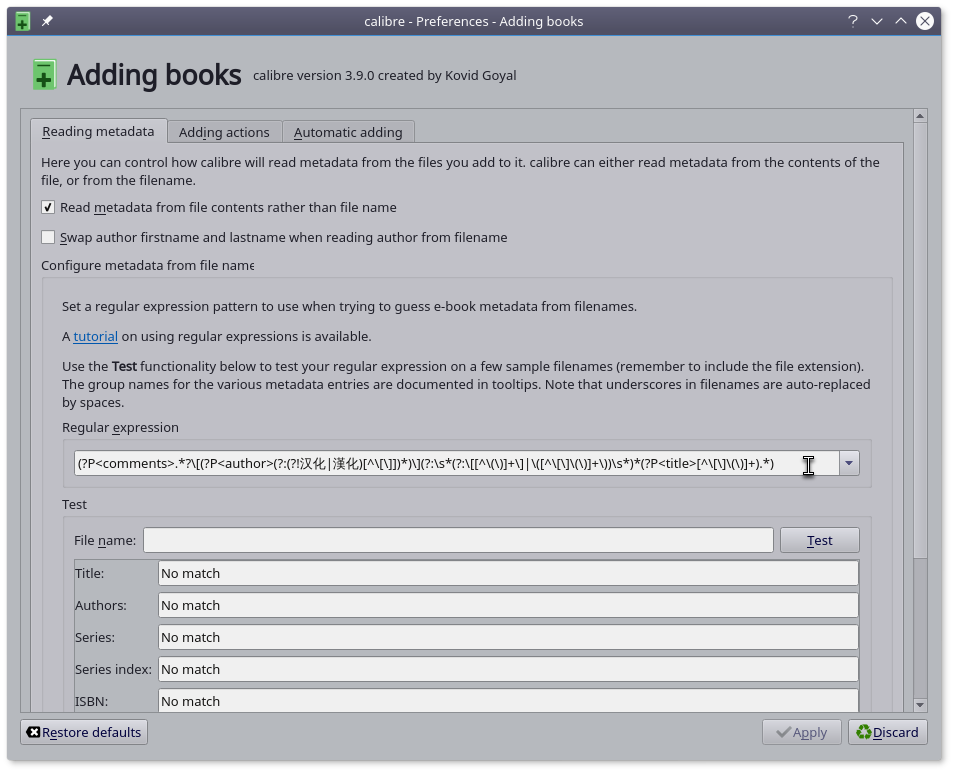
保存设置后,可以开始向Calibre书库中添加书籍,Calibre会自动识别出题名与作者。
录入高级元数据
基本元数据的录入通过Calibre自带的正则功能即可解决。
但除了题名、作者之外,图书还有许多的元数据,例如说出版信息、ISBN号、Tag、简介等。对于这些元数据的录入,Calibre提供从网络下载元数据的功能。
从网络下载元数据的方法为,点击 Edit metadata ,点击 Download metadata 按扭,然后即可开始下载元数据。
不出所料,没有找到什么元数据。点击右侧小的按扭进入下载元数据的设置界面。
在设置界面中,你可以选择数据源,可以选择要下载的元数据类型,还可以创建tag的转换规则。
但是很可惜,Calibre自带的数据源都不怎么适合于本子(对于电子书来说,还不错),使用搜索引擎也没在网上找到适合于本子的数据源插件(都没人用Calibre管理本子吗?)。
没有办法,只能自已动手,丰衣足食,自己写一个针对本子的数据源插件了。
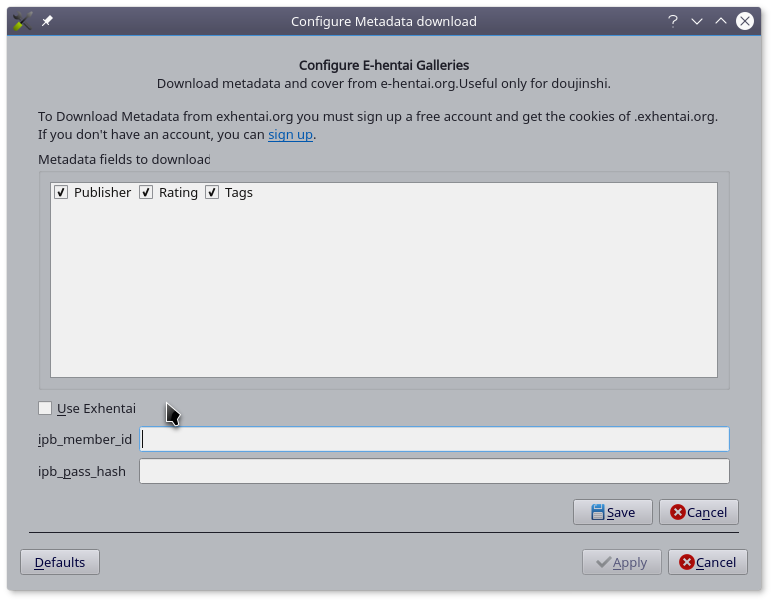
考虑到,网上大多数的本子都可以在 E-hentai 上找到,所以从E-hentai上下载本子的元数据是一个不错的选择。
由于E-hentai上,题名与作者并没有分开列出,也没有出版信息,所以该插件的主要任务是下载本子相应的tag信息。
另外,对于本子来说,什么出版社,哪一年出版的大家好像并不是很关注。大家最关心的还是tag,所以我这个插件一般情況下已经足够用了。
使用插件
点击 Edit metadata 按扭,点击 Download metadata旁的小按扭, 只保留 E-hentai Galleries,再在右上角只保留Tags 选项。
保存设置,点击 Download metadata,开始下载元数据,下载速度与你的网络有关,选择相应项目,完成下载。
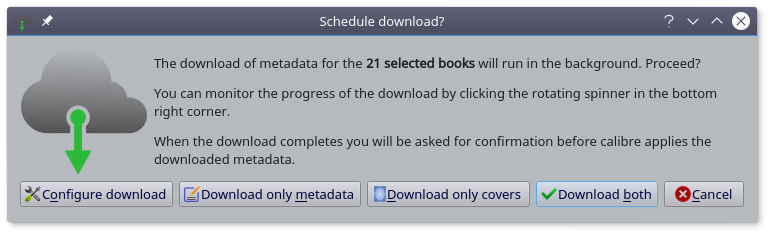
后续处理
下载完元数据,你会发现tags是长这副模样的,这可能不太符合你的期待。
Doujinshi, Female:cunnilingus, Female:females Only, Female:incest, Female:lolicon, Female:sister, Female:yuri,
对于这种情況可以使用 Tag mapper 功能进行转换。
打开 Preferences-Toolbars 选中 The main toolbar 把 Tag mapper 从左侧移动到右侧。
选中刚刚下载好元数据的书籍,点击菜单栏上 Tag mapper 按扭,然后创建转换规则即可。
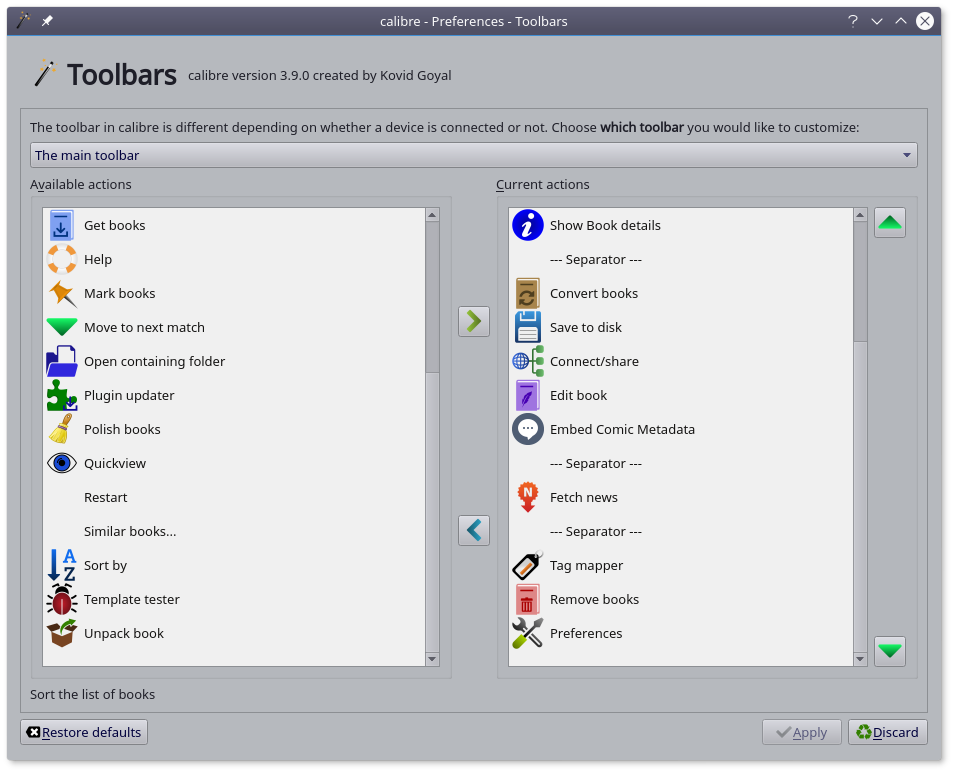
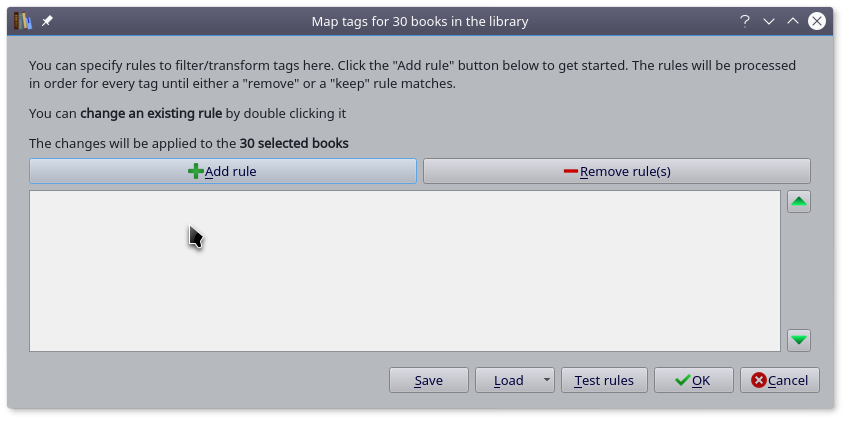
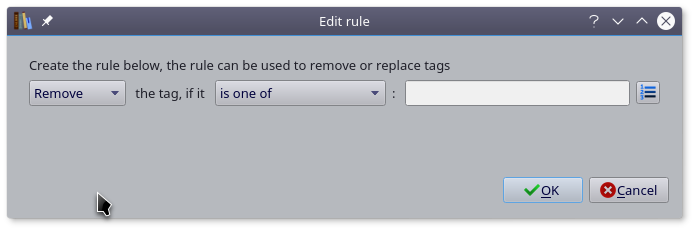
创建转换规则有点烦,我就不弄了,如果你们有谁创建好了,记的导出来和大家分享一下。
答读者问
Calibre 自带的阅读器打开本子太慢了。
Calibre 自带的阅读器,读读epub格式的速度还可以,但对于本子来说,速度就有些太慢了,毕竟Calibre的主要功能是管理而不是阅读。
对于这个问题,我的解决方法是更换阅读器,使用专用的漫画阅读器来阅读本子,更换的方法可以参见准备文件一节使用插件部分,修改cbz文件的默认打开方式即可。
对于阅读器,Linux系统下你可以使用 MComix 或者 zathura,Windows系统下你可以选择 ComicRack。
更换阅读器之后,相信你可以很快的打开本子了。
我本子都存移动硬盘了,怎么破?
对于这个问题,有两种解决办法。
你可以在电脑上安装Calibre,然后在移动硬盘上创建一个书库。这样你便有两个书库,电脑硬盘上一个,移动硬盘上一个(移动硬盘的书库用于存本子)。
然后平时不看本子时,使用电脑硬盘上的书库,看本子时,插入移动硬盘,将书库切换至移动硬盘上的书库。你可以通过主菜单上的按扭,很方便的完成这个操作。
不过我更推荐第二种方法,直接在移动硬盘上安装一个Calibre便携版 ,然后启动移动硬盘上的Calibre,在移动硬盘上创建一个本子的书库。
这种方法免去了频繁的切换书库(虽然不麻烦)。另外,移动硬盘上安装了一个便携版Calibre,你可以很方便的在不同电脑上打开你的本子库,无须重新安装Calibre。
我的本子都在nas里了,怎么办?
Calibre是一个跨平台软件,Linux、Windows、masOS均支持。
你可以在NAS上安装Calibre,使用 calibre-server 命令在NAS上创建一个内容服务器,用于与电脑、手机、Pad分享电子书。
如果你需要向书库中添加书籍,使用 NFS 将书库目录映射至本地,再在本地安装一个Calibre,用于管理书库。
注意:请保证只有一个程序正在修改书库(可通过文件权限设定,达到此目的)。否则可能会造成文件损坏。
PS1: 之前在网上找了一个在NAS上使用的 Calibre Docker。但经读者测试,这个Docker文体好像有一些问题,无法显示出中文字符。修改一下Dockerfile,把文泉驿的文体装上,可能会有用。感兴趣的可以试一试。
PS2: Calibre自带的内容服务器还是有一些问题,比如说有些epub文件打不开,有些pdf文件背景会变成奇怪的黑色,大一些的cbz文件在线阅读时会出错(手机上尤为明显)。对于这些问题,比较靠谱的解决方法是,将文件下载至手机,然后使用第三方软件打开,例如对于本子,下载到手机,然后使用 ComicRack 阅读。
结语
到这里全文便结束。
今天晚上比较清闲,把答读者问补上了。
解决出版社、出版时间、ISBN号问题的插件也列入到了计划之中,等哪天有时间就开始动手吧。
当然自己动手,丰衣足食,如果有谁有空又有能力可以自己写一个插件,如果可以开源、共享出来,也算是对绅士界的帮助吧。
长文章的排版真心难搞,图片多的长文章更是难弄。
这篇文章写完了,首先发在我的博客里,排版调整了好几次,现在的排版算是将就吧, 算不上好看也算不上难看。
然后再把文章贴到神社里,这一步真是难弄。文章中图片太多,再加之原本是图文混排用了不少类属性。虽然对文章做了一些调整,但是效果不佳。
最后只有使用删字诀,把原文尽量精简能删就删,尽量让它不带什么格式,然后得到了现在在神社中看到的这篇。
对于图床的问题,我没有微博帐号,微博图床自然是用不了。imgur确实有一点慢。然后在网上试了好几个免费图床,最后选择了sm.ms图床。测试了一下,速度挺不错的,也可以直接传图,是一个好图床。
最后,本作品采用知识共享署名-相同方式共享 3.0 未本地化版本许可协议进行许可。
琉璃神社★ACG.GY原创文章,转载请保留原文地址: http://llss.icu/wp/54512.html
")
 (32 人评价, 平均: 4.72 分 )
(32 人评价, 平均: 4.72 分 )











![[ACG周报Vol.8]这不清真!女装系列新作登场。](https://q.hacg.pics/?src=http://ww1.hacg.pics/67aeb6d9gw1f4d7b718r8j20d80ardl9.jpg)

前来考古,以前还是电脑菜鸡,没实施两步就放弃了,现在卷土重来,这calibre真是nb
没有微博号注册一个便是
关健是刚刚注册的新用户也发不了图,用不了图床呀!
由于我对我博客的域名作了一些修改,文章中的地址因此失效,大家可以通过新的地址访问,给大家带来不便,敬请谅解。
新的地址是
https://blog.bgme.me/posts/use-calibre-to-manage-your-doujinshi-2/
楼主辛苦了,顺便也分享一下我的思路吧。
虽然我存的本子不是很多(不到5000本),但是也确实感到管理的难度,所以我之前也有自行摸索解决方案。
和楼主的方案相比,可能我的方案更适用于这样的情况:1. 硬盘比较小,不能接受同一个本子存在两种不同格式占用空间;2. 本子主要存在NAS上;3. 只给自己用;
基本上我的方案有三个步骤:
1. 检查所有本子,若有不符合规范的则自动修正(比如不是zip格式,没有元数据,图片命名不合规则等),其中元数据是从exhentai自动搜索下载并作为txt文件,和图片打包在一起的。
2. 在整理好所有本子的基础上,建立sqlite数据库,并压缩本子第一张图放到thumbnails文件夹
3. 在NAS上运行用python-flask写的server端。其思路是这样的:开始时只载入sqlite数据库和thumbnails,等到点开某一个本子时再解压这个本子到临时目录,节约硬盘空间。不必担心速度问题,只给自己用的话,除非本子超大,否则这样临时解压并不影响打开速度。
感觉自己写server端比较自由,排版和功能可以用自己喜欢的(虽然就是本地exhentai换个皮而已)。
厉害!
我比较懒,喜欢用别人造好的轮子,实在没办法了才自己动手写,实在比不上层主。
有从exhentai 取得rating的脚本吗?长年累积下来不挑着看根本看不完
作者这个脚本本来就可以从exheitai上获取评分。
你可以自己试试。
还有这种操作!
技术贴,赞一下
虽然是干货,但是没图真的很难懂
作者博客里面的那篇图片挺多的,你可以去看看。
所以说大佬(某种意义上都是)都是 Linux 吗?
我也不知道,我又不是大佬?。
我曾经想过用calibre管理本子,但是因为缺少数据源放弃了。。没想到还真的有这种操作
我个人是用MangaMeeya CE 2.4来看本子
这软体也有预览功能,预览介面和Calibre感觉差不多
试了下下载tag,发现下载的时候没法连接到ex……我明明浏览器可以用ex,该复制的也复制了……
然后,下载tag的时候……会把我觉得比较关键的角色/作品舍弃掉
tag的问题是因为当初设计时,设计成脚本自动过滤掉parody、group、character、artist的tag,我已经去掉了这部分代码,你可以到github上下载最新版本。
无法连接ex,你可以使用最新版本,从exhentai下载元数据出错时,在错误页面点击 Show details ,检查错误日志,看看是哪里出错了。
不过根据我的经验应该还是cookies的问题,直接从浏览器中复制到Calibre中,复制的cookies值在结尾会带有看不见的换行符,进而导致cookies错误。
建议打开记事本,先把相应的cookies值复制到记事本中,再将相应的cookies值复制到Calibre中。
如果仍然有问题,你可以通过邮箱联系我。
另外不建议在公开场合贴日志,日志里可能会带有一些隐私信息。
图书封面可以改吗
编辑元数据,里面有个换封面的地方
请问标签映射器里保存的规则是存在哪里?
我用的移动版,在另一台电脑打开时,在原来那台电脑上写的标签映射规则全部都找不到了。
Tag映射到中文有这个Tampermonkey插件可以参考,https://greasyfork.org/zh-CN/scripts/24269-exhentai%E6%A0%87%E7%AD%BE%E5%AE%8C%E5%85%A8%E6%B1%89%E5%8C%96
不过应该怎么应用到Calibre库里面去呢,已经修改的怎么办。。。看看直接先修改一下那个calibre插件
额。。修改后了,添加直接翻译tag的选项
忘记发连接了 ==
https://github.com/troyliu0105/doujinshi_metadata_plugins
我用的是Calibre3.18.0后,在安装插件时出现如下错误,请问是什么原因?
calibre, version 3.18.0
错误: 未处理的异常: InvalidPlugin:The plugin in u’F:\\tools\\\u4f60\u7684\u672c\u5b50\u7ba1\u7406\\E-hentai Tag\\doujinshi_metadata_plugins-1.1.2.zip’ is invalid. It does not contain a top-level __init__.py file
calibre 3.18 Portable embedded-python: True is64bit: False
Windows-7-6.1.7601-SP1 Windows (’32bit’, ‘WindowsPE’)
32bit process running on 64bit windows
(‘Windows’, ‘7’, ‘6.1.7601’)
Python 2.7.12+
Windows: (‘7’, ‘6.1.7601’, ‘SP1′, u’Multiprocessor Free’)
Interface language: zh_CN
Successfully initialized third party plugins: E-hentai Galleries (1, 1, 2) && Embed Comic Metadata (1, 3, 8)
Traceback (most recent call last):
File “site-packages\calibre\gui2\preferences\plugins.py”, line 317, in add_plugin
File “site-packages\calibre\customize\ui.py”, line 461, in add_plugin
File “site-packages\calibre\customize\ui.py”, line 60, in load_plugin
File “site-packages\calibre\customize\zipplugin.py”, line 192, in load
File “site-packages\calibre\customize\zipplugin.py”, line 290, in _locate_code
InvalidPlugin: The plugin in u’F:\\tools\\\u4f60\u7684\u672c\u5b50\u7ba1\u7406\\E-hentai Tag\\doujinshi_metadata_plugins-1.1.2.zip’ is invalid. It does not contain a top-level __init__.py file
看来还是改回3.17 吧,我最近懒,没有升级。就没遇到这个问题。看来是有些什么调用出问题了。
又看了下,你的目录结构咋那么深?不对啊.
我的是Calibre3.18.0便携版,这个有什么影响吗?
下载这个文件夹[ehentai_metadata],再压缩,选中安装
我修改了一下你的代码。calibre读取文件是用get_resources(“filename”)读取的,我把tags的翻译单独拿出来放一个json file里了
1. 导入书籍时可以用正则表达式提取项目
我想提取社团名 作者名 汉化组名 题材
但这些并不存在于内置项目中
自定义项目无效 插件没有该项功能 其他内置项目也占满了
2. 部分本子封面不是第一张
要怎么便捷的调整?
难道解包后重新选择吗
1、社团名可以填到“Publisher”一栏中。
汉化组名可以和作者并列填在“Authors”一栏中,二者之间用&号隔开既可。
我文中的正则式讲求通用性,所以仅提取了题名与作者,你可以尝写下一个可以提取更多内容的正则式出来。
题材,按理来说放在tags中比较好,不过正则式提取的栏目好像没有tags一栏。
2、调整封面,你可以在Calibre作品的信息中Path栏中点击“Click to open”打开相应的文件夹,找到相应文件,使用解压缩工具(winrar、7zip等)单独打封面解压出来,然后浏览更改封面。
亦或者,使用解压缩工具打开相应文件后,重命名封面的文件名,使其在排序时位于首位,然后在Calbre按下“Set cover for the book from the selected format”按扭。
大概就这两种方法,第二种相对简单一些。
当然,从ehentai上下载封面也是一种选择。
我现在有个问题,如何导出或者导入我自己做的标签映射规则啊,在那个规则编辑界面没找到,而且在那里做修改太慢了
时隔多日,希望得到答案,谢谢
感谢楼主分享。另外麻烦问一下楼主,有没有什么好用的视频管理工具?
再来问一下,因为e站的版权问题,很多作者的资源搜不到了。
想暂时用nhentai的 tag 做补充。
不知道能否做个新版本的标签抓取?
批量下载元数据的插件虽然可以批量从eh上下载tag,但是不知道为什么只有一小部分本子可以下载下来tag,有些手动下载才能下载,还有一些干脆不能下载,但是上eh上搜索本子名是可以找到相应本子的,这是个例吗?还是我设置的有问题呢…
Mac os 的自动获取标签的插件安装的时候出错
对于从e/里站下载的本本,全网搜了一遍发现除了正则,其他也没什么信息搜刮器..然后我就做了个自动化爬取信息(tag, 作者, 标题, 评分, 语言, 原页面)并打包进cbz文件的脚本。calibre也支持按tag检索, 这下子就方便多了。
https://github.com/xiazeyu/hentaiTagger4calibre